
CONNECTION_RESET(HTTP RPC调用的Connection reset问题调研)
相信不少使用HTTP RPC作为微服务通信协议的业务会碰到偶发的connection reset错误,由于出现的几率不高,大多数对事务准确性要求不高的业务中忽略它问题也不大,或者在出现的时候做个重试也就解决了,但这个阴魂不散的错误还是让人感到头疼。
原因分析
究其原因,是因为服务间http调用通常会开启keep-alive以到达复用传输连接的目的,而keep-alive连接的关闭不是那么优雅。
可以用一段简单的Node.js代码来复现。
const http = require("http");const agent = new http.Agent({ keepAlive: true });// server has a 5 seconds default idle timeouthttp
.createServer((req, res) => {
res.write("foo\n");
res.end();
})
.listen(3000);setInterval(() => {
// using a keep-alive agent http.get("http://localhost:3000", { agent }, res => {
res.on("data", data => {
//ignore });
})}, 5000); // sending request on 5s interval so it's easy to hit idle timeout
这段代码中客户端以5秒的频率,通过一个保持的socket连接向服务端发起请求,而在Node.js中,服务端的keep-alive timeout时间默认也是5秒,这个timeout是指对于空闲了5秒没有通信的socket连接,服务端会主动关闭它,避免资源占用膨胀。
也就是说客户端在每次向服务端发起请求的时间,刚好也是服务端准备关闭socket连接的时间。在一个理想的流程中,服务端关闭连接后,客户端会马上收到socket close事件,这时就可以把该连接从连接池中移除,下一次http请求就需要创建新的socket连接再发出了。
可是由于这个时间太不巧了,服务端在关闭连接之后,客户端还没来得及收到或者处理socket close事件,下一个请求已经准备发出了,这时候客户端拿着关闭的socket向服务端发送消息,服务端的TCP栈看到连接已经关闭了,就会回复一个RST包(connect reset),也就是客户端收到的ECONNRESET错误了。
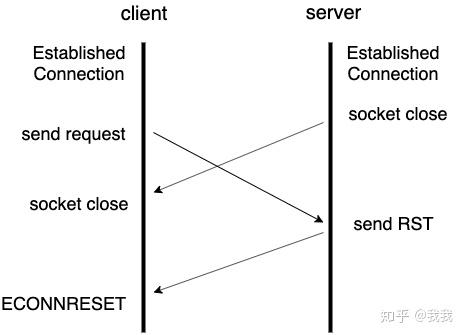

错误处理
按照前面讲的原因,碰到ECONNRESET错误是请求发向了已经关闭的socket连接,那么是不是碰到这个错误重试一下就行了呢?或者把keep-alive timeout的时间设置的长一些,让这个巧合出现的几率变小。
用重试解决问题
在下结论之前,不妨参考一下业界的做法。
我们首先看到Node.js社区流行的http库request是如何处理的:
if (self.req._reusedSocket && error.code === 'ECONNRESET') {
self.agent = {addRequest: ForeverAgent.prototype.addRequestNoreuse.bind(self.agent)}
self.start()
self.req.end()
return}
可以看到这里做了一个检查,只有发现请求复用了之前已经建立过连接的socket,才会对这个请求进行重试。
看到这里自然有个疑问,如果不做这个检查会有什么后果?我们先带着这个疑问看看工业界比较流行的语言golang怎么处理,经过一番搜索发现了golang的issue里存在不少讨论,并且都参照了chromium项目处理错误的代码,chromium项目的代码质量比较高,并且有大量详细的注释,通过阅读chromium代码可以加深对这个问题的理解。
于是看到chromium项目里也有类似的检查。
bool HttpNetworkTransaction::ShouldResendRequest() const {
bool connection_is_proven = stream_->IsConnectionReused();
bool has_received_headers = GetResponseHeaders() != nullptr;
// NOTE: we resend a request only if we reused a keep-alive connection. // This automatically prevents an infinite resend loop because we'll run // out of the cached keep-alive connections eventually. if (connection_is_proven && !has_received_headers)
return true;
return false;}
注释里说,做这个检查是为了防止无限循环,当消耗完连接池里所有的连接之后,只会再有一次额外的尝试了,回顾上面Node.js request库的重试,还加了保证重试时一定使用新的连接来发送请求(addRequestNoreuse)。
按照注释中的描述,存在一种情况,在连接成功后第一次发送请求会收到ECONNRESET错误,这时如果重试,会进入ECONNRESET循环。那么怎么才能进入这种状态呢。只有服务端正常接受连接建立,并且在接收到请求数据的时候才中断连接,才会进入这种状态。但是如果请求数据有问题,一般倾向于从应用层协议上返回错误,不太会用RST包来直接中断连接。
为了更好的把这个问题搞清楚,我们先来梳理一下ECONNRESET这个错误是如何从操作系统网络层返回到应用层的。
首先ECONNRESET是一个系统级错误,由操作系统网络栈返回给应用层,Linux 的man pages文档里是这样描述这个错误的: Connection reset (POSIX.1-2001).,指向了POSIX规范,而在POSIX.1-2001规范中只有简单的一句话描述了这个系统错误:The connection was forcibly closed by a peer.
在Linux代码中看到这个错误的产生是收到了一个TCP RST(reset)包,同时在连接的不同状态,RST可能导致不同的错误。
/* When we get a reset we do this. */void tcp_reset(struct sock *sk){
trace_tcp_receive_reset(sk);
/* We want the right error as BSD sees it (and indeed as we do). */
switch (sk->sk_state) {
case TCP_SYN_SENT:
sk->sk_err = ECONNREFUSED;
break;
case TCP_CLOSE_WAIT:
sk->sk_err = EPIPE;
break;
case TCP_CLOSE:
return;
default:
sk->sk_err = ECONNRESET;
}
...
比如在连接建立阶段收到RST,这个错误会是ECONNREFUSED。联想到我们对一个没有服务监听的端口发送请求,得到的错误码确实是ECONNREFUSED而不是ECONNRESET。
const http = require('http')http.get("http://localhost:3333")// Error: connect ECONNREFUSED 127.0.0.1:3333
既然不用担心远程地址不存在监听服务而导致死循环,我们还需要检查socket是否被复用吗。
带着这个疑问我在chromium开发组里提了一个问题,得到这样的回复:
A server returning ERR_CONNECTION_RESET on a fresh socket, however, means that there is some sort of server (or middlebox) issue. And yes, we can get a reset at that point (buggy SSL implementations seem to be big fans of resetting sockets during SSL negotiation when they’re sad, for instance).
按照这个说法,如果在一个刚刚建立成功的“新鲜”连接上发送请求,得到服务端返回的RST,说明服务端的TCP栈实现是不正确的。而这种错误的实现在现实中也确实可以找到例子,比如有些SSL协议的实现会有这样的行为:在 TCP连接上建立SSL通道时,碰到某些失败情况会返回RST,google一番可以发现有不少人碰到了这个问题。
为了避免现实世界的这类问题,那么这个检查是合理的,退一万步讲,如果我们只是为了解决最早说的keep-alive连接timeout关闭的问题,socketReused这个判断明确把场景限制在这个范围了。
通过提前丢弃可能超时的连接解决问题
除了碰到这个错误再重试,国内流行的web框架eggjs还有另外个做法:既然服务端存在keep-alive超时,那么客户端在超时之前主动丢掉这个连接,就自然不会碰到这个尴尬的巧合了。
具体步骤是这样:服务端把自己的keep-alive timeout值通过response header返回给客户端,客户端记录这个时间,把网络延迟考虑在内,在快要到这个时间前,把连接废弃掉。
更详细的解释eggjs这篇专栏文章介绍的很清楚,就不再赘述了。
这个做法的好处是提前避免了问题的出现,而不用等到出现了再解决。但是需要服务端修改支持,在多语言的技术架构中,相对不是那么灵活,另外也存在一些对网络延迟的假设,比如提前500ms丢弃连接,对一些比较严谨的开发者来说可能不是那么完美。
针对幂等请求的重试
前面提到的golang issue里,还说到golang针对部分幂等方法做了重试,所以connection reset这个问题没有出现在GET等方法的请求中。不过现实中也会有大量使用POST方法的请求没有被考虑到,况且也不能保证GET请求是遵循幂等的,golang的这个做法远非完善。
后来为了把修复覆盖到所有幂等的请求中,golang增加了幂等header的支持:如果header中存在{X-}Idempotency-Key字段,那么这个请求就会被认为是幂等的,golang的http client也会自动重试这类请求。
这个做法依赖工程师对每个请求幂等性作出清楚的标识,从可实施性上很难称得上是个好的方案。并且,对于非幂等的请求,碰到ECONNRESET就没有办法了。
那么对于收到ECONNRESET错误的请求,是否有办法确认服务端没有接收或者处理过请求,依次来决定是否发出重试呢,如果是一开始讨论的keep-alive timeout连接断开问题,服务端先于客户端发出请求之前已经断开连接了,自然不会有接收并处理了请求的可能。但是令人纠结的点在于,ECONNRESET来源于TCP连接强制终止,TCP连接强制终止的可能性很多,我们不能做出百分百的假设服务端没有在处理完消息之后返回一个TCP RST包。
rfc2616中的实践部分就提到keep-alive timeout,并建议不要重试非幂等的请求。
A client, server, or proxy MAY close the transport connection at any
time. For example, a client might have started to send a new request
at the same time that the server has decided to close the “idle”
connection. From the server’s point of view, the connection is being
closed while it was idle, but from the client’s point of view, a
request is in progress.Client software SHOULD reopen the
transport connection and retransmit the aborted sequence of requests
without user interaction so long as the request sequence is
idempotent (see section 9.1.2).
连接的关闭确认
回顾问题的根源是服务端决定关闭连接的时候没有经过客户端确认就直接关闭了通道,联想到TCP连接关闭的时候有4次挥手断开流程,那么是不是存在可能利用TCP的这个机制,让服务端和客户端协同关闭连接从而避免这个问题呢。
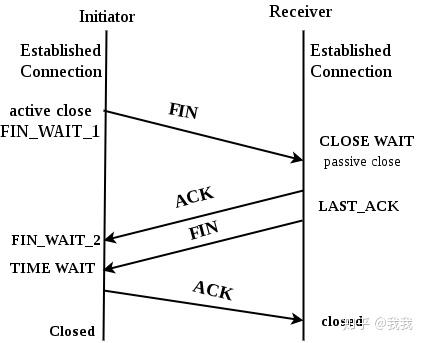
我们先来确认一下TCP协议中关于终止连接部分的规范和实现,如果目的是避免keep-alive timeout导致的ECONNRESET问题,必须假设发起连接中断的服务端,在发出关闭FIN信号,等待client端也发出FIN之前是可以接受处理请求的。
这个假设是否能成立呢,我们看看rfc1122中关于TCP连接关闭的描述:
The normal TCP close sequence delivers buffered data
reliably in both directions. Since the two directions of a
TCP connection are closed independently, it is possible for
a connection to be “half closed,” i.e., closed in only one
direction, and a host is permitted to continue sending data
in the open direction on a half-closed connection.
这里提到了half-close这个概念,发起关闭的一方进入这个状态之后,仍然可以接收数据,直到另一方也关闭了连接。Node.js关于Socket的操作实现了half-close: Node.js Socket.end() 这个方法的描述是 “Half-closes the socket. i.e., it sends a FIN packet. It is possible the server will still send some data.” 注意这句话是以客户端作为关闭发起方来描述的,这里的server指的是关闭信号接收方,在我们的例子里,关闭信号由服务端首先发起,所以这个方法的描述和我们碰到的问题也对应起来了。但是我们观测到的现象是发起关闭的服务端没有等到客户端回应就关闭了通道,在接收到客户端数据时会返回RST包。
检查Node.js HttpServer源码,发现socket在超时之后被强行销毁,而不是调用Socket.end进入half-closed状态。
function socketOnTimeout() {
const req = this.parser && this.parser.incoming;
const reqTimeout = req && !req.complete && req.emit('timeout', this);
const res = this._httpMessage;
const resTimeout = res && res.emit('timeout', this);
const serverTimeout = this.server.emit('timeout', this);
if (!reqTimeout && !resTimeout && !serverTimeout)
this.destroy(); // 调用了destroy方法而不是end}
那么如果把这里的destroy调用替换成end呢?在修改并重新编译后的Node.js上执行文章开头那段测试代码,发现错误还是存在,只不过错误信息不一样了:
Error: socket hang up at connResetException (internal/errors.js:566:14) at Socket.socketOnEnd (_http_client.js:437:23) at Socket.emit (events.js:215:7) at endReadableNT (_stream_readable.js:1193:12) at processTicksAndRejections (internal/process/task_queues.js:80:21)
原因是正如前面引用的rfc中所说,half-closed状态的服务端,虽然可以接收数据,但是并不能发送数据了。而这个测试里服务端确实收到了请求消息(可以打日志验证),但是客户端在尝试读取response时还是会出现connResetException错误。
很不幸,这个思路到这里就被证明行不通了,网上有些文章说TCP的(graceful close)half close可以解决这个问题,并不准确。
改进的协议
grpc health check
说到底,http并不是一个为rpc场景设计的协议,想想一个专用的rpc协议会存在哪些机制可以避免这个问题呢。
检查了grpc的特性介绍,并没有发现针对这个问题的直接描述,但是提到grpc的连接保活机制,通过周期性的ping frame,idle connection会被不断激活,也就避免了timeout终止。
With gRPC periodically sending HTTP/2 PING frames on connections, the perception of a non-idle connection is created. Endpoints using the aforementioned idle kill rule would pass over killing these connections.
回到使用http协议的场景,也可以借用这个思路,周期性地通过已经建立的连接发送ping请求保持连接不被关闭。不过由于在繁忙的业务中,同时存在的http连接数会比较多,造成的额外网络开销也是需要考虑的。
http2
我们知道grpc是构建在http2上的,那么http2相对于http存在哪些改进,是否可以避免这个问题呢,如果http2解决了,那么构建在其之上的grpc自然不用担心了。
果然在http2 rfc里有一部分介绍了http2的请求可靠机制,似乎专门考虑到了我们碰到的这个问题。
在介绍这个机制之前我们先简单了解一下http2协议。
我们知道在 http1 中,由于一个连接同时只能处理一个请求,要增加并发量,如果对每个请求都建立单独的连接又比较浪费,实践中通常会在客户端和服务端之间维护一个连接池,每次发送请求从连接池中挑选可用的连接。
而在http2中,一个连接可以同时承载多个请求,每个请求在一个抽象的stream中完成,每个stream有自增的id标识。
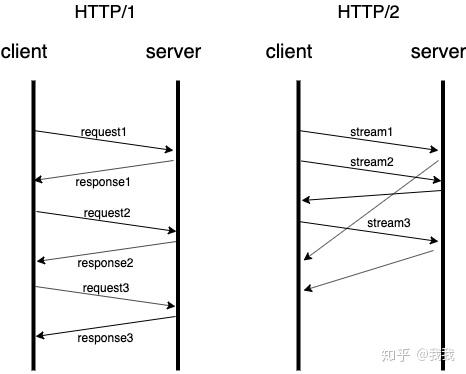
再回到上面引用rfc中的文字,
o The GOAWAY frame indicates the highest stream number that might
have been processed. Requests on streams with higher numbers are
therefore guaranteed to be safe to retry.
o The REFUSED_STREAM error code can be included in a RST_STREAM
frame to indicate that the stream is being closed prior to any
processing having occurred. Any request that was sent on the
reset stream can be safely retried.
这里介绍了http2的两个机制:
-
GOAWAY:服务端在关闭连接之前会通过id最大的stream发送一个GOAWAY frame,客户端收到这个frame之后就知道stream id大于或等于GOAWAY所在的stream的所有消息都是没有被接收的,可以通过新的连接重试。
-
REFUSED_STREAM:服务端如果要通过RST_STREAM重置一个stream(有点类似TCP RST),可以在RST_STREAM frame里包含一个REFUSED_STREAM错误码,告知客户端这个请求没有被处理过,可以安全的重试。回想TCP的RST复杂就在于接收方无法确定发起RST的场景和原因,RST_STREAM的错误码就解决了这个问题。
总结
介绍完几种针对connection reset错误的处理思路之后,我们可以看到针对http1.1有效的处理措施有3个,但似乎仍旧没有一个清晰的结论,究竟哪种方法是最好的,我们要么接受请求可能丢失,要么接受请求可能重复处理,或者接受两者同时存在的情况,再不然就换用更可靠的RPC协议比如grpc或者http2。似乎http1.1 RPC就是一个无法做到exactly-once的消息管道。复杂的现实世界就是这样,我们越想接近正确,就要做更多的工作,比如让业务方法尽可能的达到幂等性,才能放心的在出错时重试,或者建立后置的数据异常检查恢复机制,在出现脏数据时也有途径去修补。
不过在调查的这个问题的同时也回顾巩固了对HTTP和TCP协议栈的理解,在具体业务场合也能做出更好的选择。
版权声明:本文内容由网友提供,该文观点仅代表作者本人。本站(http://www.liekang.com/)仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 3933150@qq.com 举报,一经查实,本站将立刻删除。
版权声明:本文内容由作者小仓提供,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至907991599@qq.com 举报,一经查实,本站将立刻删除。如若转载,请注明出处:https://www.shaisu.com/293794.html